- 模糊测试
前言
- 本文主要参考文献《模糊测试技术综述》仁泽众等,文中图片也基本来源于此文献
简述
- 针对目标程序生成随机字符流,对程序进行测试,发现可能的漏洞
发展历程
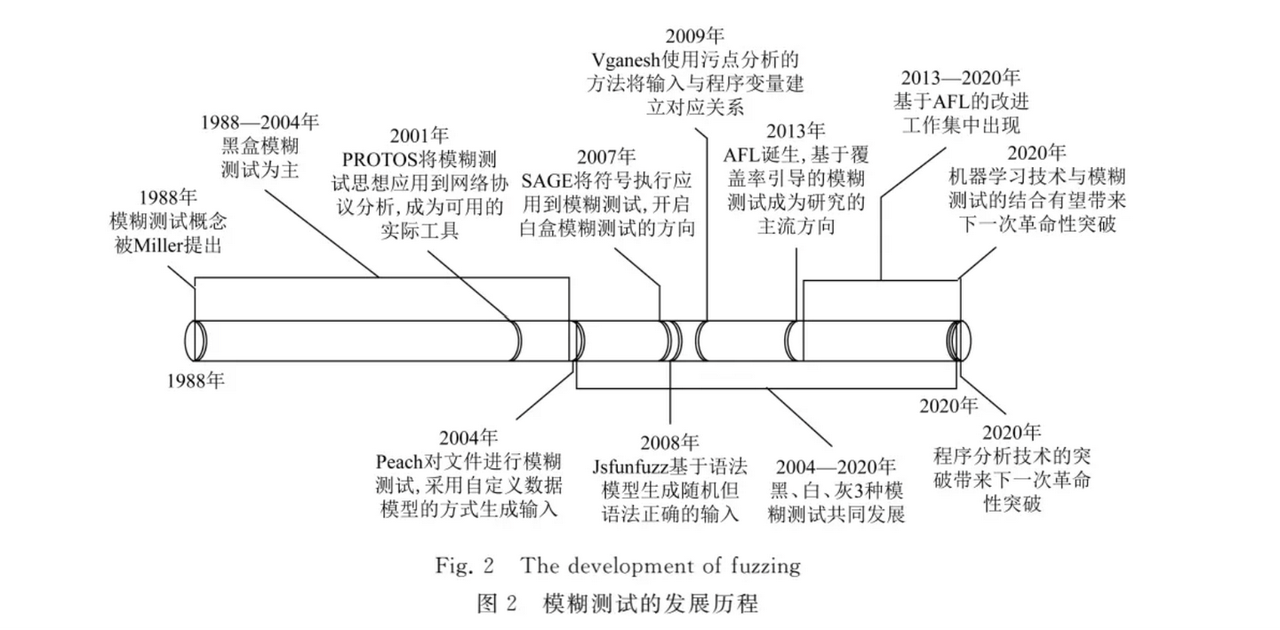
基于AFL的模糊测试方法

工作流程
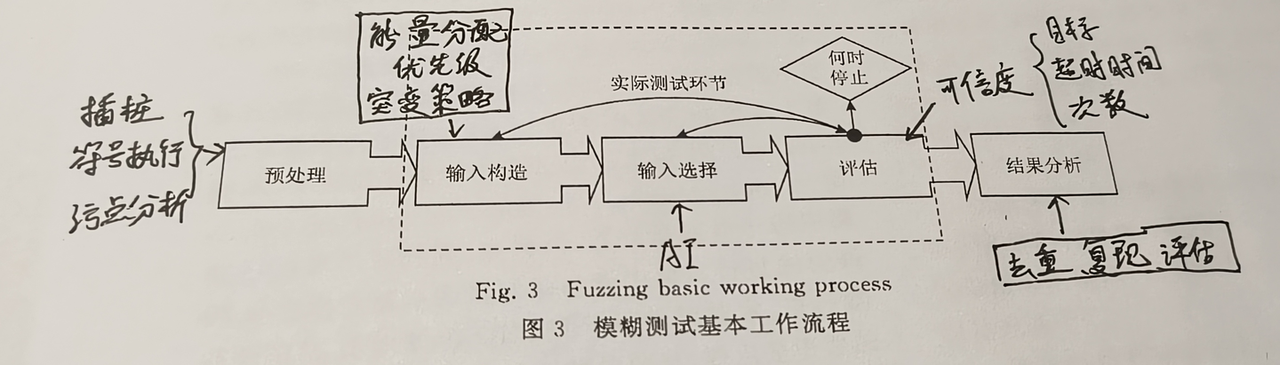
预处理
获取目标的相关信息
- 输入数据格式
- 目标内部结构
- 状态变化检测准备
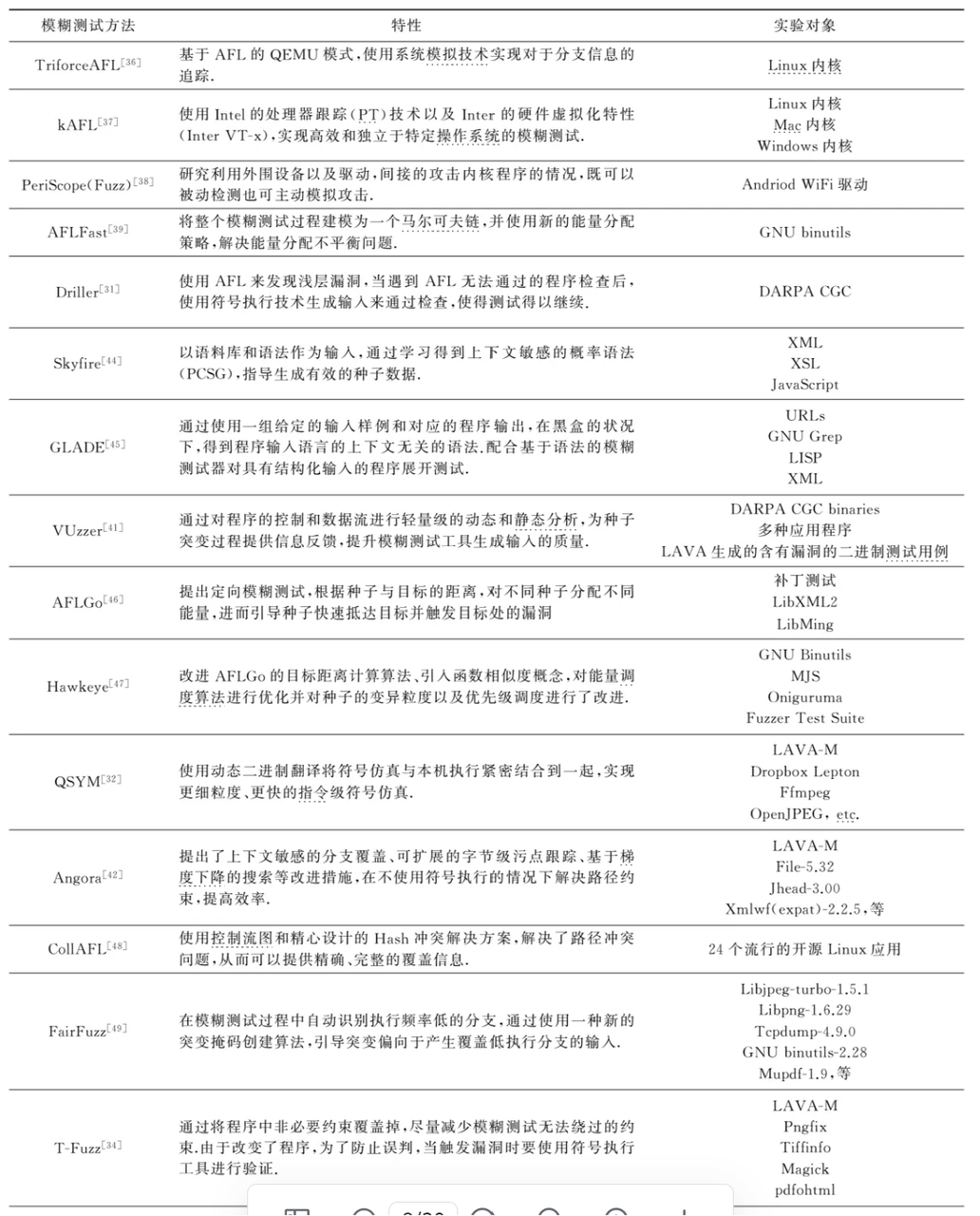
涉及的主要技术
插桩
- 静态插桩【中间编译(LLVM-IR)】
- 动态插桩【qemu模拟】
符号执行
简述:将程序行为的推理归结为逻辑领域推理
符号执行可以分成动态和静态。但无论哪一种,最大的两个限制都是路径爆炸和约束求解问题
- 路径爆炸【构成原因:循环分支等】
- 约束求解失败【构成原因:取Hash等操作】
动态符号执行
- 路径爆炸的问题仍然存在,因为这个跟程序的控制流有关,无法从根源上避免。但是可以只选择重要的路径进行启发式探索。
- 对于约束求解问题,动态执行可以用一些实际值替换的方法,但是这样也会丢失路径,可能造成结果不完整。
污点分析
分类以及流程
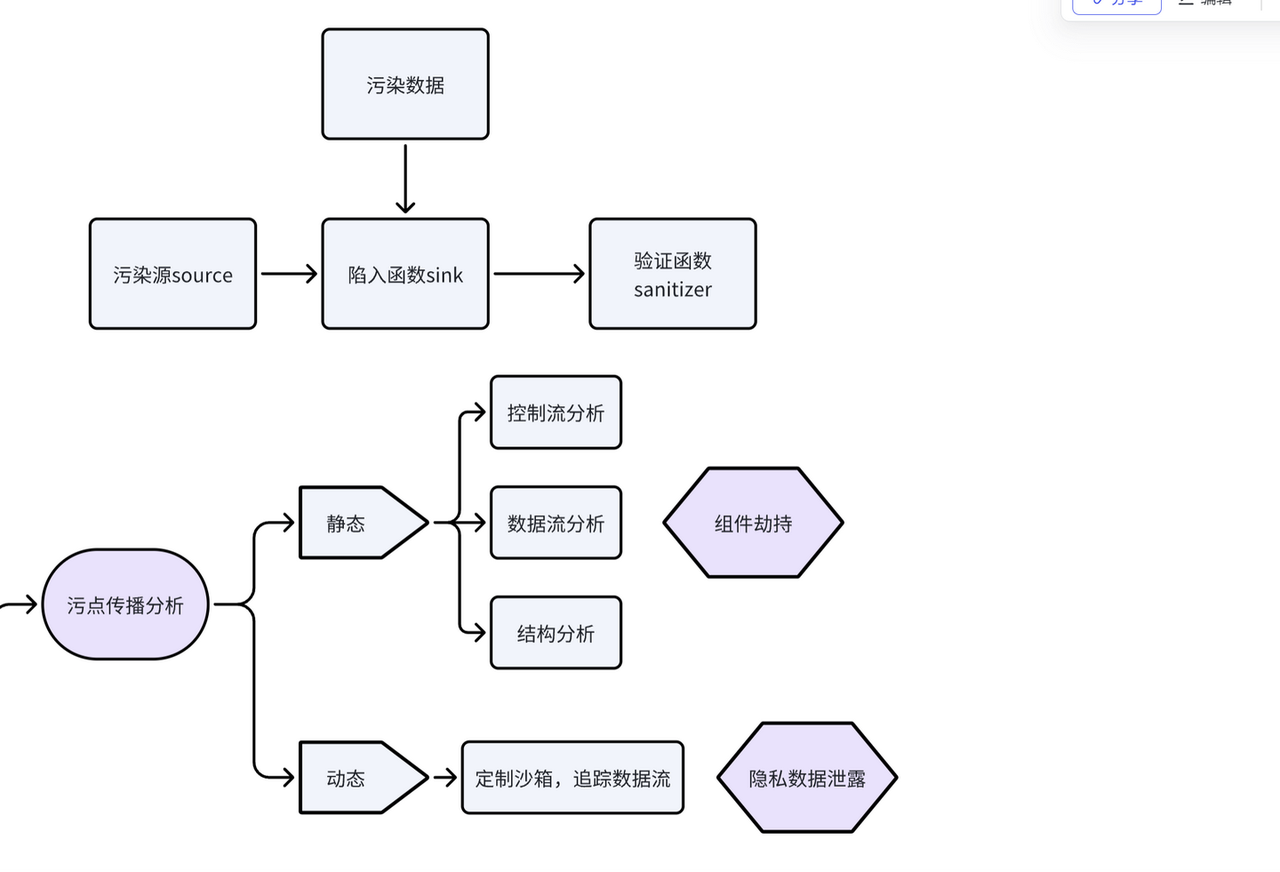
类型划分
黑盒模糊测试
优点:设计简单,开发和检测速度快
缺点:会生成大量无效输入,测试覆盖率相对较低、很难检测深层漏洞
PROTOS、Peach、DELTA、IFuzzer、IMF、IoT Fuzzer
白盒模糊测试
优点:可以生成高质量输入数据、覆盖率高、深层漏洞检测
缺点:一般都会采用符号执行,容易引发的问题上面已经描述过了。消耗的资源也会更大
加速符号执行速度
- 允许符号重用之前的计算结果【Pangolin】
- 利用字段级的信息优化符号执行【Intriguer】
分离模糊测试和符号执行
- 符号执行只作为验证方法过滤误报【T-Fuzz】
灰盒模糊测试
黑白结合就是灰(bushi)
AFL
编译时插桩,获取边缘覆盖率信息。并使用进化算法,将边覆盖率作为算法的适应函数,使得模糊测试向覆盖面增大的方向进行
输入构造
- 构造出用于模糊测试的输入数据
种子获取
考虑因素
- 输入数据执行速度
- 路径访问频率
- 路径访问深度
- 路径覆盖面
种子筛选
种子能量分配
种子的能量大小代表该种子可以生成的数据的多少
所以模糊测试有一个好的能量分配策略是十分重要的
两个改进方向
- 缩短达到检测能力极限的时间,覆盖率最大化【AFLfast】
- 引导模糊测试方向【AFLGo、Hawkeye】
其实就是深度和广度的追求
种子优先级
这个的研究过程演变有点类似于从队列到优先队列,设法寻找一个评估标准实现优先队列,确定种子的优先级
一些影响因素和做法
进化算法,通过适应度函数对输入评估【AFL】
三级队列:种子是否触发新路径、种子与目标种子的相似度、种子是否包含目标函数【Hawkeye】
维持覆盖率不变的条件下,通过反复删除种子的不同部分,尝试缩短种子大小【AFL】
这个优化主要是因为越短的数据被执行所需要的时间一般更短
种子突变
- 在获得了优质的种子之后,想要生成大量的数据就依靠种子的突变了
一些突变方式
- 比特翻转(bitGflips)
- 简单算数运算(simplearithmetic)
- 覆盖(overGwriting)
- 插入 (inserting)
- 删除 (deleting)
- 拼接(splice)
你可以想象一个字符串可以怎么被修改(掐头去尾替换什么的)来理解这个东西
分类
黑盒突变
- 不依赖于目标相关信息,依照随机突变策略对种子进行突变
- 可以快速生成大量输入,当然,大量不代表有效
程序导向性突变
简述:通过程序分析技术得到种子与程序状态的关系,以此制定突变策略
感知突变策略,诱导走向更深的路径【VUzzer】
性能导向性突变
简述:根据输入数据和模糊测试评估指标的关系指定突变策略
突变策略的一些考虑因素
确定突变位置
- 可伸缩字节级别的污点分析【Angora】
- 污点推断技术获取污点属性【GERYONE】
- 只选择种子特定位置进行突变,防止关键字段被修改【Skyfire】
- 对于结构性数据,根据语义划分成不同的字段进行突变【ProFuzzer】
覆盖、替换、插入所使用的备选字符的有效性
程序执行状态
输入选择
- 主要是进行数据有效性判断,尽可能过滤掉无效数据,节省执行时间
在这个阶段和后面的评估阶段,可以考虑机器学习的应用,进行半自动化或者自动化处理
但同时也有新的痛点
- 数据不平衡问题。有效和无效数据样本不平衡,于机器学习不利
- 通用性的问题,不同目标的模糊测试数据不同,很难求通解,这样训练的数据来源、准确性也就成了问题
一般评估标准
覆盖率
- 上下文无关的边覆盖率【AFL】
- 上下问敏感的分支覆盖率【Angora】
- 块覆盖率【VUzzer】
暴漏漏洞平均时间
结语
- 不管什么样的测试方式、突变策略、评估方法
- 方法本身没有好坏,能够拿着需求的钉子去寻找解决问题的锤子,对症下药、灵活应用才是核心
收集一些Android端Fuzz相关的论文,没准哪天会用到
- Atlas: Automating Cross-Language Fuzzing on Android Closed-Source Libraries