- ML+AMD的攻击、扰动选择树、零知识场景
ML+AMD前置知识背景
基于机器学习(ML)的 Android 恶意软件检测 (AMD) 方法能够有效地识别和分类恶意软件。这一类AMD的主要工作可以分为两部分:恶意样本特征提取 + 模型训练
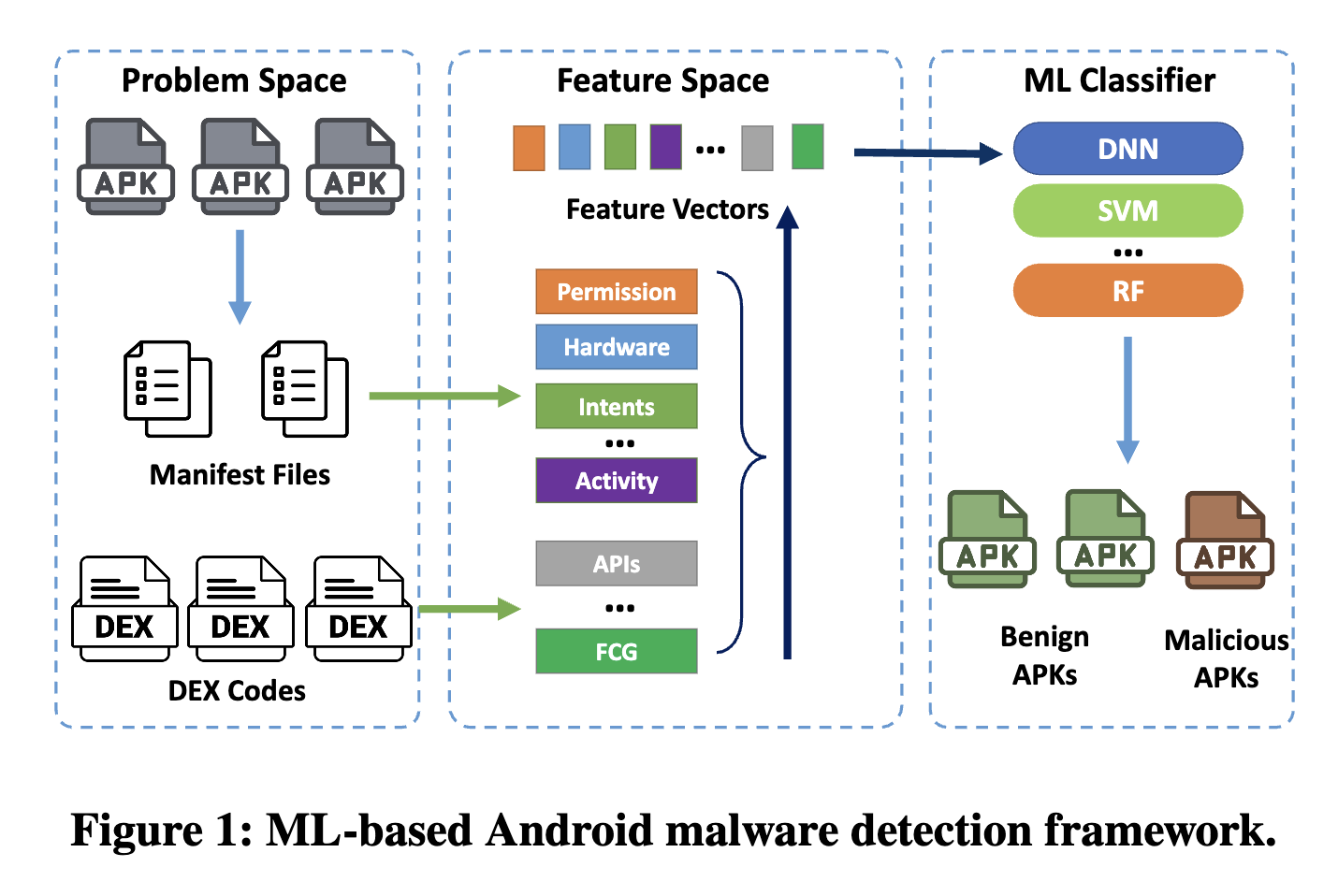
ML虽然对于AMD来讲十分有用,但这种方式也存在致命的弱点:
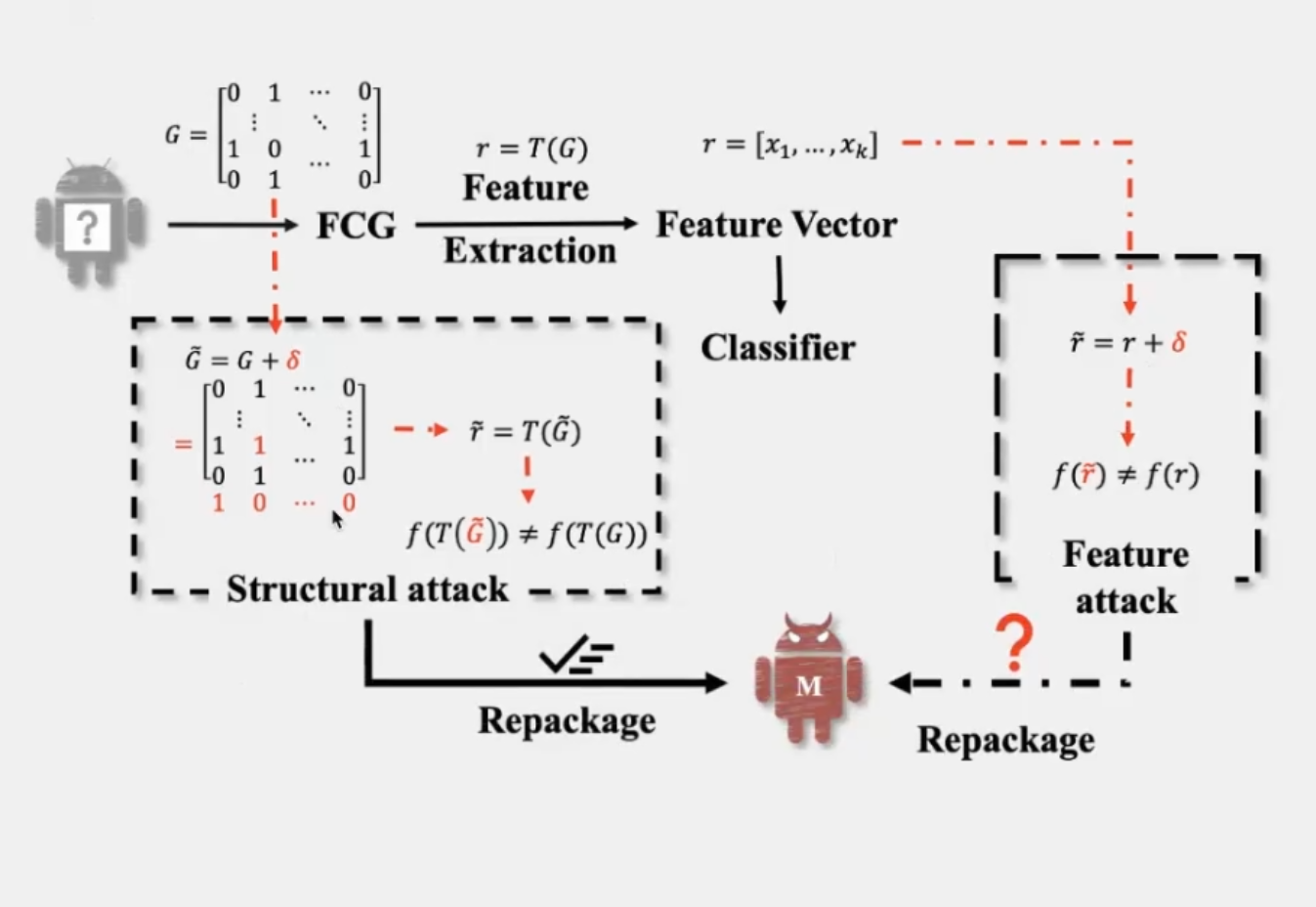
向量扰动:针对于模型训练的特点去构造扰动,导致特征向量越过 ML 分类器的决策边界,从而绕过恶意软件检测器的眼睛
结构攻击:如果检测器是基于api调用序列来检测恶意软件的,那攻击者就可以通过一些手段直接从源码层面重构恶意样本的api调用模式,绕过检测
提取的特征【字节码、指令、api调用序列等】
训练方式的选择【SVM、RF、DNN等】
事实上作为攻击者来讲,这种攻击思路是需要一定前置假设的,由此引出了下面的问题挑战:
challenges
挑战Ⅰ:样本扰动空间庞大且异质
扰动样本为安卓应用,本身具有非常复杂的组织结构。相比图片、文本等多媒体数据,在安卓应用中的扰动空间会更加复杂多样
挑战Ⅱ:零知识场景挑战
目前提出的很多攻击假设它们对于AMD模型有很多前置的认知(比如说数据集、特征空间和模型参数),这与现实情况是有很大差异的
对于AMD模型,攻击方能够获得的一般只有置信度等一些粗粒度的信息,面对这种模糊的信息,如何对AMD去做针对性的攻击是一个很大的挑战,这个情况也就是零知识场景
因此文章提出了针对这种场景的一种攻击思路
总体思想
- 攻击的核心是进行针对性的扰动,文章中将扰动选择过程抽象为树中的路径采样
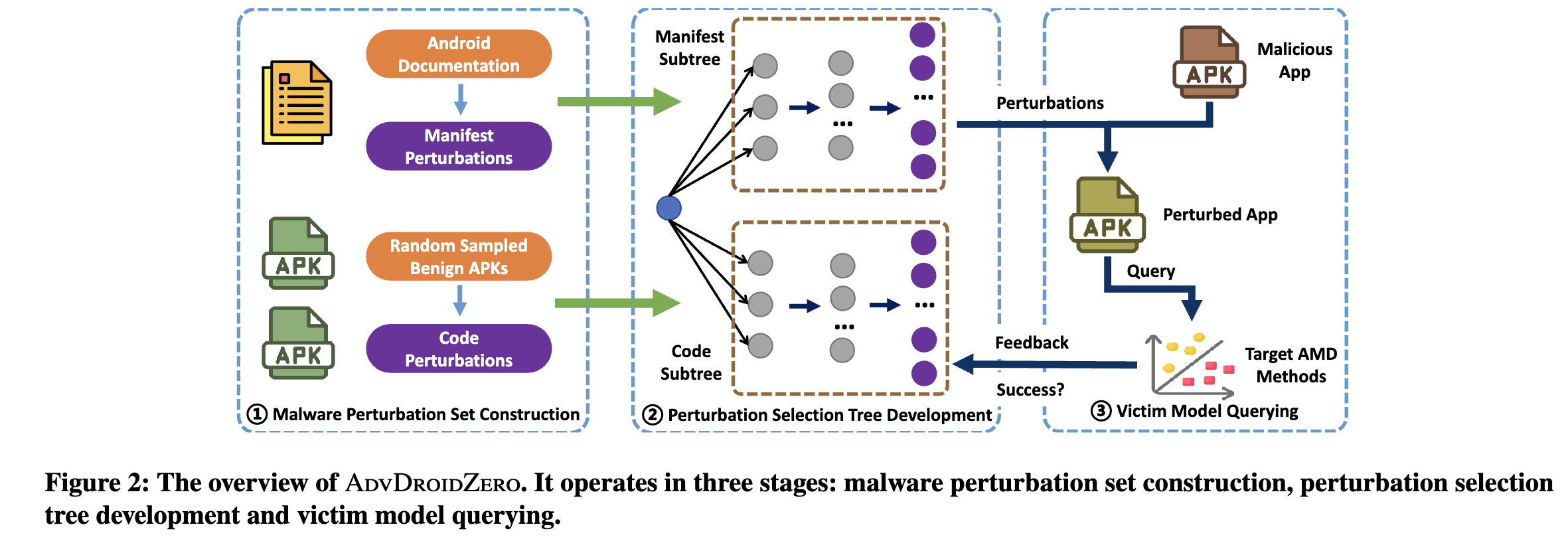
扰动攻击一共被分成了三个部分:
构建恶意软件扰动集–>扰动选择树开发–>受害者模型查询–>feedback
恶意软件扰动集构建
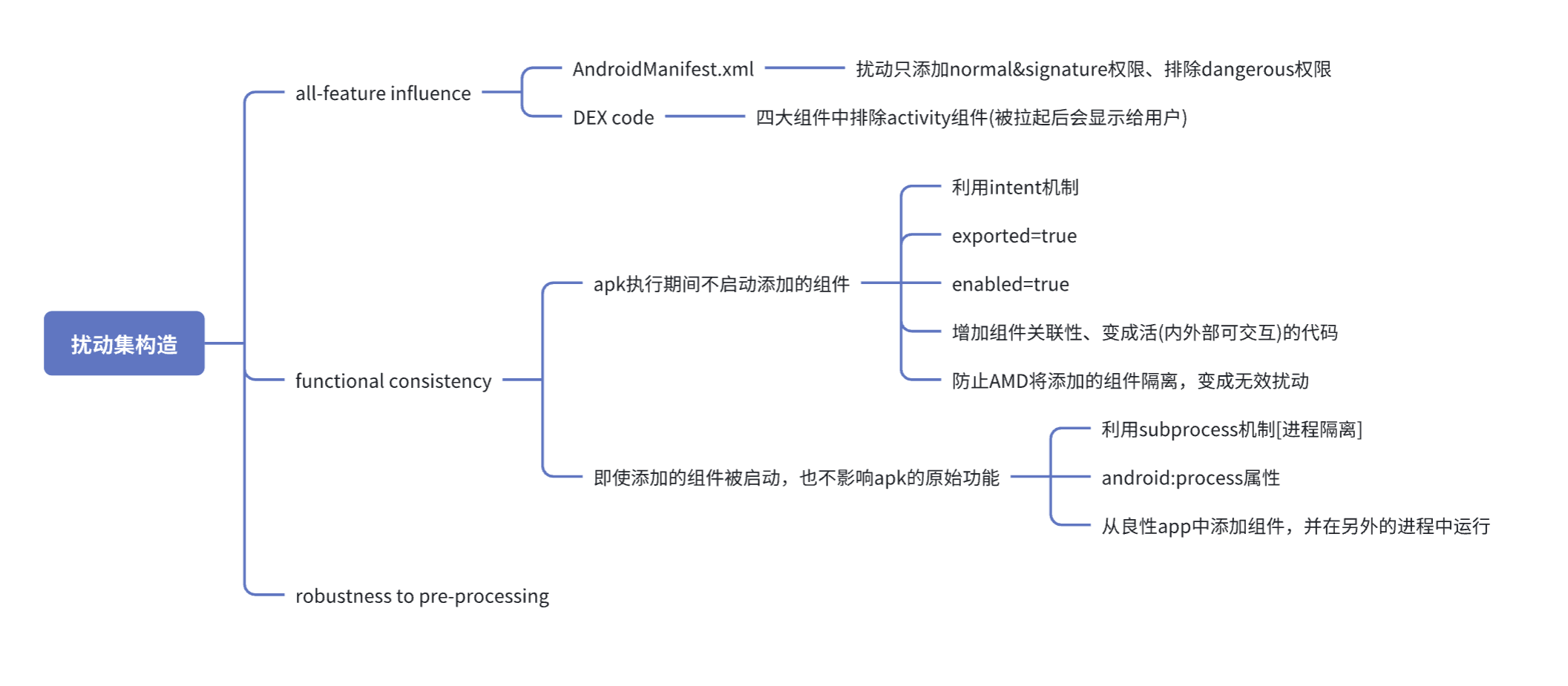
扰动集构造主要考虑了三个方面的问题:全特征影响、功能一致性、预处理的鲁棒性
具体的扰动分成两个层面:
- 针对语法功能(静态功能)(例如权限)manifest perturbations
- 针对语义特征(动态特征)(例如函数调用)code perturbations
扰动选择树开发
- 由上至下粒度逐渐细化,每个叶节点表示一个细分的扰动
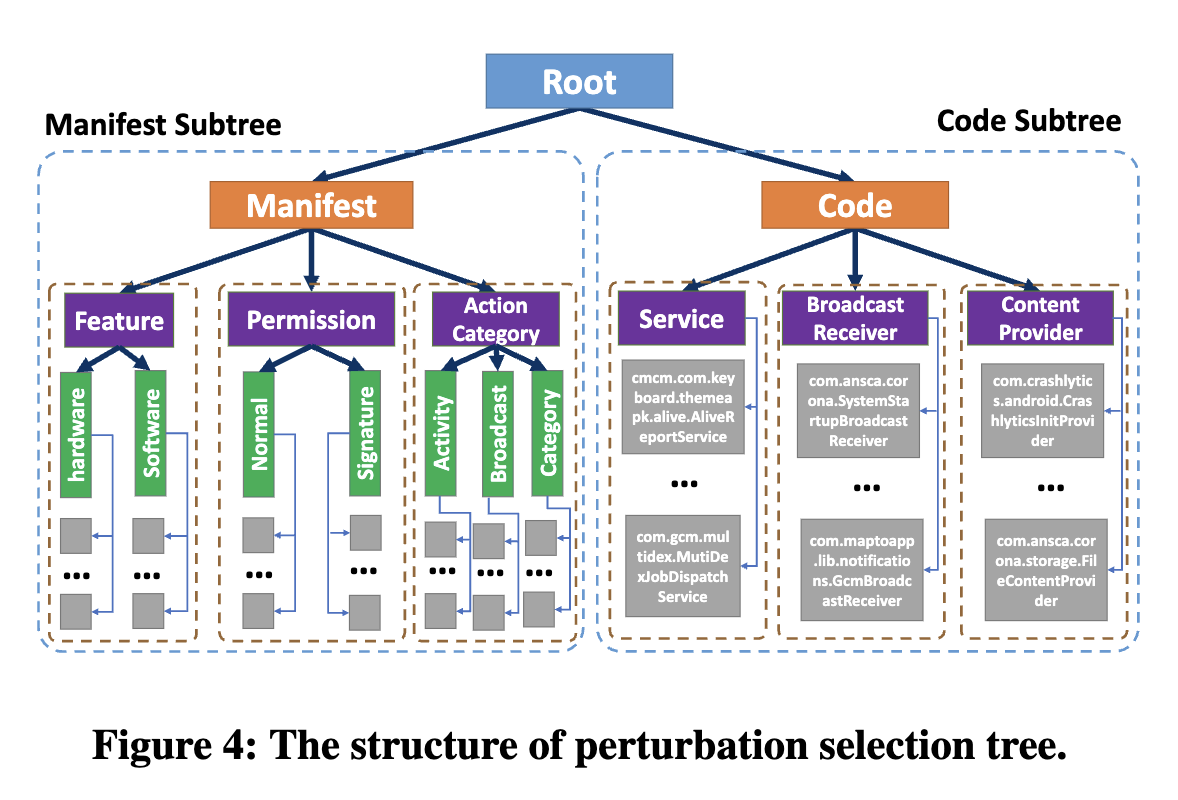
受害者模型查询
攻击是一个迭代的过程
- 选择恶意软件扰动
- 扰动恶意应用程序
- 获取模型反馈
- 更新扰动选择树
评估
这里作者对四种AMD方法做了评估,分别是:
Drebin、Drebin-DL、MaMadroid、APIGraph
方法分析类型核心特征模型优势局限性Drebin静态权限、API、字符串线性SVM高效、可解释易被混淆绕过Drebin-DL静态同Drebin,嵌入表示深度学习捕捉复杂模式数据/算力需求高,黑盒问题MaMadroid动态API调用序列、事件流随机森林抗混淆、检测运行时行为资源消耗大,覆盖率依赖触发APIGraph混合API调用图结构图神经网络建模复杂交互、检测多阶段攻击计算复杂,依赖图构建质量
攻击性能
考虑两个维度:
攻击效果:在给定查询预算范围内生成能够对抗AMD的恶意软件
攻击成本:
- 人为因素【扰动集构造和扰动树开发,包括分析最新的Android文档进行版本迭代】
- 运行时开销
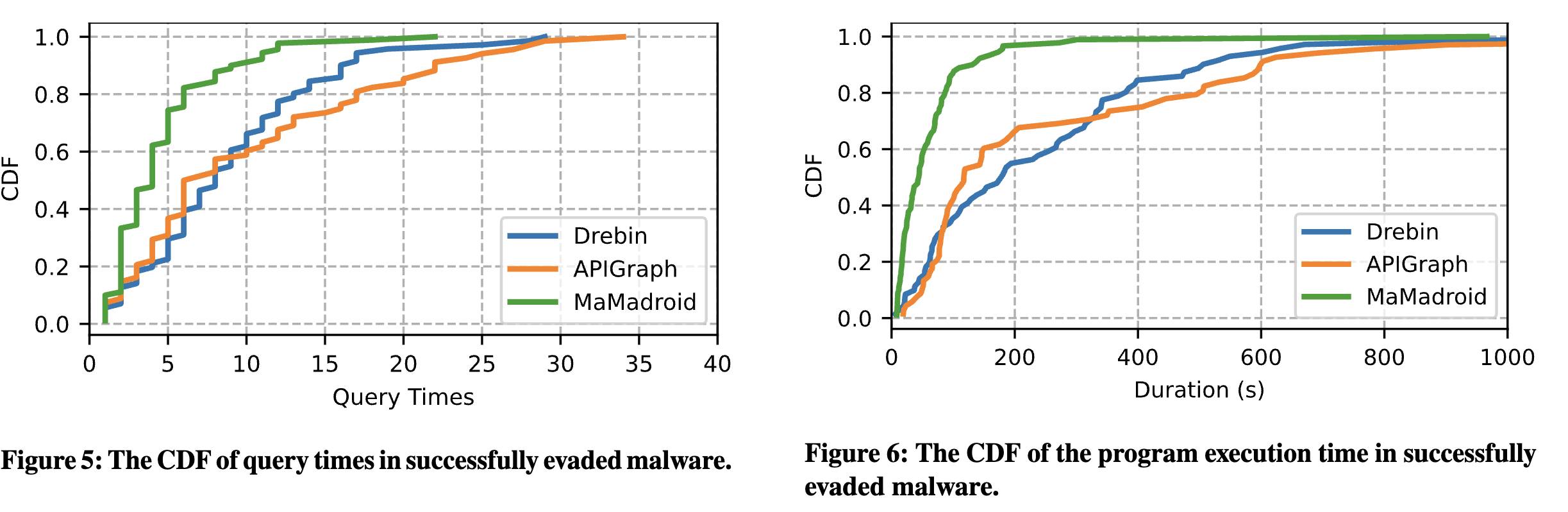
动态防御攻击评估
- Android 应用程序中的组件通常实现独立的功能并具有丰富的语义,这使得它们很可能由沙箱触发
- 由于这些用于扰动的组件源自良性应用程序,因此它们本质上没有恶意行为
- 动态防御会花费过多时间分析这些良性的扰动代码,从而导致恶意代码识别率下降
未来的挑战
- 混合防御框架
- 扰动集的完整性